
部署自己的搜索引擎實現關鍵詞優化
2010-03-22 10:48?來源
經常看到朋友們討論關鍵詞優化,也見過朋友費心地“積累”關鍵詞。這里為大家分享一個用自架搜索引擎來做關鍵詞優化的經驗。
聲明:此經驗適用于有一定技術能力的站,要求服務器有java運行環境,如JDK,TOMCAT。如果你不具備這些條件的話,也可以以手工的方式變相實現,但比較費時間。
這 個經驗是被javaeye論壇啟發的。在網上搜技術資料時,這個論壇出現的機率極高。點進去看,大多是一些文章列表。用文章列表的形式去迎合關鍵詞,匹配 的機率當然就大了。而你的文章當然不同于硬堆出來的關鍵詞,搜索引擎看到這么多匹配的正規內容,自然會喜歡。如果從用戶體驗上來講,你把自己資料庫中最相 關的東西展示出來給用戶看,自然也是最佳用戶體驗,比起讓用戶找類目,一頁一頁地翻,肯定是強百倍了。
道理很簡單,我重點講解怎么去實現。我的實現方案用到了開源搜索引擎solr和開源的中文分詞系統paoding(國人貢獻的庖丁解牛中文分詞軟件)。
solr是基于開源索引lucene的,這兩者皆是apache開源組織推出的,官網地址為:
lucene: http://lucene.apache.org/
solr: http://lucene.apache.org/solr/ (solr是lucene下的子項目,solr可讀作“掃啦”)
順便也提一下lucene下的另一子項目nutch,這是一個搜索引擎爬蟲,可以爬intranet或internet,很酷吧!如果你想玩高級的采集,不防學一學,當然要有java編程功底。
轉入正題,先說lucene的作用。lucene是一個索引系統,它可以對內容進行關鍵詞索引,這有點像數據庫,區別在于后者不僅要索引,還要維護更多的其 它內容,比如數據關系。但后者在全文檢索上功能比較差,高級的數據庫系統才支持全文檢索,而像被廣大使用的mysql數據庫,則沒有這項功能。 lucene則不一樣,它的意義不在于存儲和維護數據,它生來就是做索引的,所以它會對文本內容進行分詞索引。打個比方,如果你的文本內容里有 “hello world\"一句話,那么它會分析出hello,world兩個詞,并會把此條內容作為一個索引條目添加到hello和world兩個關鍵詞索引目錄中。 這是不同于SQL里的like查詢的,數據庫沒有對字段內容進行分析,只是針對字段做了索引,當你要like查詢字段內空時,它實際上是一條一條的做字符串匹配,這樣效率很低下,無法承受重壓。所以很少有人用like做大業務量的搜索。
有lucene了,solr是干什么的?lucene 只提供了編程接口,而solr是個開箱即用的東西。請參考官方的說明,相信你很快就可以架起一個solr搜索服務。solr所需要配置的只有一個地方,就是schema.xml,你要在這里配上你的CMS系統最終文章所用到的字段,比如作者,分類,標題,內容等等,同時要配好這些字段的類型。不同的字段類 型會影響其搜索表現。solr架好了,如何使用呢?它提供了兩個接口(簡單吧,只有兩個接口),一個是update,一個是select,分別對應更新與 查詢(刪除屬于更新)。update的具體實現就是向基指定URL POST一個XML文檔。關鍵部分格式大致如下: 本文“”來源:http://www.coweal.com/keji/design/13568.html,轉載必須保留網址。
編輯:
- 熱門內容
- 網友熱議
- 精彩內容
 官方否認4G降速 5G來了
官方否認4G降速 5G來了 2018十大網絡用語盤點
2018十大網絡用語盤點 人人網被賣了
人人網被賣了 部分相似結果已經被
部分相似結果已經被 我經常登錄的幾個S
我經常登錄的幾個S dedecms圖集縮略圖功能
dedecms圖集縮略圖功能 提交Alexa網站登錄入口
提交Alexa網站登錄入口 不良買家利用淘寶商
不良買家利用淘寶商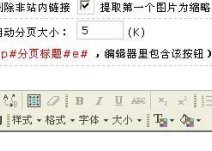 解決織夢dede所有版本
解決織夢dede所有版本